Table of Contents
글을 시작하며
안녕하세요. 정말 오랜만입니다. 한동안 현생이 바쁘다 라는 핑계로 블로그에 글을 자주 적지 못하였는데요. 오랜만에 글을 적네요. 이번엔 application layer 에 관한 이야기를 할까 합니다. 사실 저 역시 주니어 개발자 임에도 불구하고 참 감사히도 code review 를 부탁받는 경우, 그리고 실무중 코드를 작성하는 경우 굉장히 단순한 부분만을 지켜도 비교적 우아한 application 이 작성된다는 점을 느끼고는 이 주제를 꼭 다루고 싶었습니다. 물론 지금도 모자란 부분이 많기에 열심히 공부중이랍니다.
첨언하자면... 저는 클린코드와 클린아키텍처를 처음 접한때, 이건 실무에서 있을수 없는 환상이야 라고 생각하던 사람 이었습니다. 그러나 약 1년전 책을 다시 읽곤, 제 더러운 예전 코드를 전부 재작성 해봤습니다. 순간 내가 그냥 모르는 거였구나란 사실을 깨닳고 깊은 반성을 했답니다.
행여 오해하실까 말씀드리면 저는 클린 아키텍처나 객체지향, 혹은 시스템 디자인이나 디자인패턴등을 잘 아는 사람이 아니라고 생각하고, 지금도 그저 열심히 공부중인 개발자일 뿐입니다.
어쩌다 보니 현 회사의 초기부터 개발을 함께 해볼수 있었고, 이 단계에서 약 3년이 넘는 시간동안 늘어나는 사람과 이로인해 오는 기존코드의 문제점들을 지켜보며 이렇게 하면 힘들어지는구나를 참 많이 느꼈는데요. 이과정에서 느낀 "그래도 이정도는 지켜주면 비교적 덜 고생했을 수 있겠구나" 하는 부분들을 글로서 풀어내려 합니다.
이 글은 clean architecture 나 domain driven design. 혹은 object oriented 에 기반한 설계에 다가가기 이전 단계의 초석을 다지는데 도움이 되었으면 하는 목적으로 작성합니다.
제 기준 해당 부분의 공통적으로 다가가기 위한 가장 기초가 되는 Layer 와 depth 의 개념을 이야기 합니다.
제 개인적인 견해가 많이 섞여있는 글입니다. 좋은 의견이나 제가 잘못알고 있는점, 배울점이 있다면 언제나 피드백은 환영합니다! 이야기를 시작해볼까요?
Layer 란 무엇인가
이야기에 앞서 과연 이 Layer 란 무엇인가에 대하여 간단히 살펴보고 가면 좋을것 같습니다. 아마도 이 글을 읽으시는 분들중 상당히 많은 분들은 Robert C. Martin 의 클린아키텍처를 읽어보셨을것 같은데요. 혹시 읽어보시지 않으셨다면 꼭 읽어보시는 것을 추천하고 싶습니다. 저는 두번째 읽는 순간 어느 한부분에 눈이 확 뜨이는 느낌을 받았는데, 정말 좋은 책이랍니다. 그럼 아주 유명한 이 개념도를 한번 보고 가시죠.

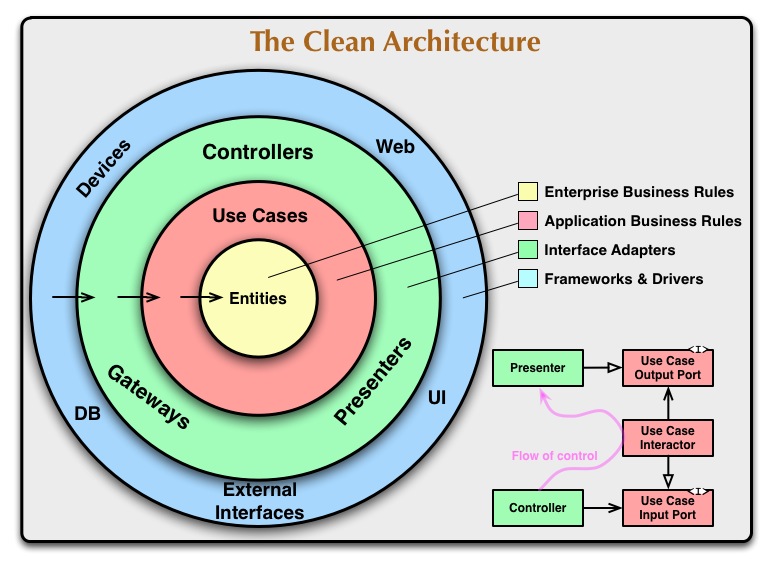
layer 란 단어 그대로의 뜻을 해석하자면 층입니다. 이 말인 즉슨 우리가 작성하는 application 에도 층이란 것이 존재한다는 것이지요. 편의상 앞으로 계층이란 표현을 사용하겠습니다. 앞서 드린 이야기처럼 이 글에선 위 이미지에 나와있는 부분들을 상세히 설명하지 않습니다. 다만 쉽게 이해할 수 있는 간단한 개념을 정확히 이해하면 좋을듯 싶은데요. 어플리케이션엔 계층이란 것이 존재합니다. 그리고 이 계층들은 각자 본인이 맞은바의 역할이 명확히 존재하지요. 이 역할들은 어떻게 나뉠까요? 비교적 간단히 알아보고 넘어가볼까 합니다.
가장 기초적인 개념에 의해 나뉜 역할은 크게 다음과 같습니다.
-
Entitiy:
Database혹은데이터를 가져오는 추체와 소통하여 가져온 값들을, 어플리케이션 세계의 객체와 매핑해주는 역할을 해주는 계층입니다. Database 의 설계와는 또 별개로 이부분의 설계를 어떻게 하느냐에 따라 객체간의 연결점을 끊고, 이어주는 것에 대한 부분에 상당한 차이를 만들어 낼 수 있습니다. 용도에 따라 스스로의 값을 검증하는 등 순수한 자신의 상태에 관련한 로직이 담길 가능성이 있습니다. 현 시점 가장 깊은 곳에 위치합니다. 조금더 정확히 표현하자면 설계 방식에 따라 달라질 수는 있지만 변화가 가장 적게 일어나는 Entity 를 기준으로, 이를 repository, 혹은 read, write 등의 용도에 맞게 변경해주는 기능들과 연관이 생길 수 있습니다. 현시점, Database 의 값을 가져와 어떤곳에 담아준다 정도로만 이해해도 충분할듯 싶습니다. -
Repository: 데이터 베이스와 소통하기 위한
sql관련 코드가 이곳에 정의됩니다. 이곳은UseCase/Service를 담당하는 영역과 가깝게 소통할 가능성이 큽니다. ORM 을 사용하셔도, 혹은 사용하지 않으셔도 크게 다르지 않습니다. 이부분은 용도에 의해 Read 와 Write 의 구현체가 따로 분리될 가능성이 있습니다. 후에도 언급할 터이지만, Read 와 Write 는 엄연히 갖는 관심사가 다른 영역입니다. 데이터를 읽고 쓰고, 가공하는 부분은 서로 관심사가 분명히 다르고 이에 따른 코드는 최대한 분리하시는 것을 권장해 드리고 싶습니다. -
UseCase/Service: 이부분은 보통 흔히 말하는
interface로 정의될 영역입니다. interface 로 사용되는 케이스를 정의하고 실제 구현체를 정의한 interface 로 주입받아 해당 케이스를 만족하는 구현체라면 블럭처럼 쉽게 갈아끼우거나, 내가 해당 케이스에 상세 구현내용을 각 상황별로 유연히 구현하여 주입시킬 수 있도록 도와주는 계층입니다. 이부분 역시 Database 와 소통 이외의 여타 케이스별 구현체가 생길 수 있는 가능성이 있습니다. 현 시점 interface 까지 생각하지 않으셔도 좋습니다. 다만 이부분은 실제로 함수를 실행하기 위한 controller 등의 말단에서 접근하는 계층과 밀접한 부분이 될 가능성이 큽니다. 하나하나의 움직임 혹은 작업의 단위를 기준으로 구현됩니다. Service/UseCase 등 작은 단위의 행위로 묶음을 만든 계층을 구현해 사용을 하는 경우도 있지만 현시점 그부분까지는 다루지 않겠습니다. -
Controller: 어떠한 요청에 대한 마중을 하는 녀석입니다. 외부에서 내 서버에 어떠한 자원을 요청하는 경우 이 계층을 통해 접근합니다. 이부분은 행위의 묶음을 표현한 레이어가 존재하지 않는 경우 대부분
절차를 정의하게 됩니다. 행여 오해하실까 말씀드리자면 Service 를 하나 하나 나열할 수도 있고, 이를 묶은 새로운 단위의 레이어가 있을때는 그것들을 순서대로 나열할 수 있습니다. 혹은 api 하나당 1:1 로 대응되는 함수를 정의 하는 경우는 해당 레이어가 1:1 로 매핑되어 사용됩니다. 아래 간단한 예시를 작성해 둡니다.
// controller
type Controller interface {
PostSignUp() http.HandlerFunc
}
type controller struct {
db database.Database
}
func NewController(db database.Database) Controller {
return &controller{
db: db,
}
}
// service/usecase 를 구현한 구현체를 나열한 경우
func(c *controller) PostSignUp() http.handlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
// ...
// 프로필을 가져오고
ggp, err := social.NewGoogleApi(params.AccessToken).Do()
// 유저를 만든뒤
userService := user.NewUserService(c.db)
u, _ = userService.Create(&u)
// 토큰을 만들어 설정
actk, rftk := token.GenerateTokens(&u)
token.SetCookieTokens(actk, rftk)
// set response
}
}
// service/usecase 를 묶은 구현체를 나열한 경우
func(c *controller) PostSignUp() http.handlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
// ...
// 프로필을 받아와 유저를 만드는 행동의 묶음
authService := auth.NewAuthService(c.db)
u, _ := authService.GetGoogleProfileAndCreateUser(params.AccessToken)
// 토큰을 만들어서 쿠키를 설정하는 행동의 묶음
token.GenerateTokenAndSetCookieTokien(&u)
// set response
}
}
// 해당 controller 에서 실행하는 모든 행동을 하나의 함수로 묶은 경우
func(c *controller) PostSignUp() http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
// ...
authService := auth.NewAuthService(c.db)
authService.PostSignUp(params.AccessToken)
// set response
}
}
후에 기회가 된다면 조금더 자세히 언급하겠지만 추상화의 수준이 높은경우와 반대의 경우는 장단점이 분명히 존재합니다. 이를 상황에 따라, 혹은 어플리케이션의 특성, 팀의 특성에 따라 선택하는 것은 결국엔 경험의 영역인지라 무조건 한가지 방법이 좋다고는 이야기하지 못할것 같습니다.
자 여기까지 이미 아실만한 분들은 다 아실만한 기본적인 계층에 대한 설명을 해보았습니다. 제가 왜 굳이 이 부분을 따로 언급했을까요? 이 계층에 대한 이해가 없이는. 동 계층간의 간섭이 어떤 결과를 초래하는지. 나아가 어쩔수 없이 그래야만 한다면 이게 괜찮은 상황인지를 구분하기 위해서는 위와 같은 가장 기본적인 레이어의 확실한 이해가 필요하기 때문입니다.
그럼 여태 살펴본 계층의 개념과 계층간 관계의 흐름을 이어서 살펴 보겠습니다.
- 기본적으로 각 계층은 각자 내 바로 한층 아래의 영역에 접근합니다.
- 각 계층은 나와 같은 형제의 계층에 간섭하지 않습니다. 다만 위의 계층에서 서로 협력하고 상호작용을 할 뿐 입니다. 표현 혹은 절차를 정의하기 위한 Controller 등의 영역을 제외한 계층은 오직 하나의 동작으로서 비교적 최대한 간결히 정의됩니다. 행동을 정의하지 않습니다. 달리기로 예를 들자면, 다리를 드는 행위 하나만을 정의합니다.
- 데이터의 흐름은 안에서 밖으로 나갈수록. 좀더 쉽게는 1층에서 위로 올라갈수록 구체화 됩니다. 이말의 의미는 가장 날것의 데이터가 무언가를 표현하기 위해 정제되어 간다는 것을 의미합니다. 내게 요청을 보낸 대상에게 건내는 데이터의 크기는 커져가지만, Entity 를 기준으로 하는 데이터가 말단에 가서는 반토막이 될 수도 있는것 처럼요. 여기서 분명히 해 두어야 할 것은 정제가 되어가는 데이터는 순수한 Model 에 가까운 데이터를 의미합니다. 특정 Entity 가 조합되어 만들어낸 결과물을 의미하지 않습니다.
// 아래와 같은 데이터가 전체라면
{
id:..,
name:..,
age:..,
created_at:..,
updated_at:..
}
-> 간단히는 여기서 정제가 되어 created_at 이나 updated_at 등의 요소가
사라지는 것을 의미합니다.
// 결과는 아래와 같습니다
{
id:..,
name:..,
age:..
}
- 계층의 표현력은 위로 올라갈 수록 구체화 됩니다. 이는 결과 데이터의 구체화 와도 이어지는 자연스러운 흐름인데요. 예를들어 유저를 찾는 어떤 함수가 로그인 이라는 행동중 일부를 표현한다는 사실은 위로 올라갈수록 분명해 집니다. Service 단의 코드만을 보고는 행동 전체를 유추할 필요가 없다는 뜻입니다. 다만 어떤 한가지의 명확한 동작을 최대한 순수하게 표현하는 계층입니다.
이쯤이면 레이어에 대한 기본적인 개념 정의는 끝난것 같습니다. 여기까지 알아본 바, 계층이 안에서 밖을 향할수록. 혹은 낮은곳에서 높은곳을 향할수록 무언가를 표현하기 위한 요소들이 구체화 되는군요. 사실 여기까지만 분명이 이해를 하셨다면 다음으로 설명할 실수는 하지 않을 가능성이 큰데요. 그럼에도 불구하고 말입니다. 위 개념은 그다지 어려워 보이지 않는데.
이토록 계층이 명확한데. 이렇게나 역할이 분명한데. 왜 코드는 자꾸만 지저분해지고, 우리를 고통스럽게 만드는 걸까요? 자 여기서 잠시 깊이 와 응집 대한 이야기를 해볼까 합니다.
깊이가 깊지 않은 코드를 작성한다는 것
어플리케이션을 작성하며 코드의 depth 를 생각한다는 것은 굉장히 중요한 일이라 생각합니다. 이는 추상화 라는 주제와도 긴밀한 관계를 가지고 있는데요. 사실 요지는 굉장히 간단합니다. 추상화의 수준을 가능한 동일하게 맞춘다 라는 부분을 신경쓰면 되는 것이지요. 백엔드와 프론트엔드 코드를 작성시는 상황에 따라 형태자체는 조금 달라질 수 있으나, 바탕이 되는 개념은 동일하다 봅니다. 아래 간단한 코드를 살펴보겠습니다.
// React component
function 추상화 수준이 맞추어지지 않은 경우() {
return (
<div>
<Header />
<form>
<button>click</button>
</form>
<Footer />
</div>
)
}
function 추상화 수준이 맞추어진 경우1() {
return (
<div>
<Header />
<Body />
<Footer />
</div>
)
}
function 추상화 수준이 맞추어진 경우2() {
return (
<div>
<header>
<nav>
<ul>
<li>
</li>
{/*...*/}
</ul>
</nav>
</header>
<form>
<button>click</button>
</form>
<footer>
{/*...*/}
</footer>
</div>
)
}
// backend controller
func(c *controller) 추상화 수준이 맞추어지지 않은 경우() {
// ...
order, _ := orderService.FindById(id)
user, _ := userRepository.FindById(order.userID)
}
func(c *controller) 추상화 수준이 맞추어진 경우() {
//...
order, _ := orderService.FindById(id)
user, _ := userService.FindById(id)
}
위의 코드를 보시면 대부분 제가 이야기 하고자 하는 의도를 이해하실 것이라 생각하는데요. 읽기 좋은 코드란 단순히 길이가 길지 않은 코드를 의미하는 것이 아닙니다. 또한 길이가 길다고 나쁜 코드가 아닙니다. 개인적으론 가능한 추상화의 수준을 맞추는 것을 우선시 하고, 이후 코드를 읽기 적절한 길이로 수정 하는것을 권장드리고 싶습니다.
물론 리얼월드에선 이전 코드를 리펙터링하는 중이라던지, 구조를 개선하는 중엔 보기 힘든 과도기의 시기를 충분히 겪을 수 있습니다. 다만 각 계층별 추상화의 정도를 균일하게 맞추는데 성공하신다면 어플리케이션의 어느 부분에서 코드를 살펴 보아도 항상 함수의 깊이가 동일하다는 점을 유지시킬 수 있을 것입니다.
저는 개인적으론 이 코드의 깊이에 관해서는 frontend 의 코드를 작성할 때 더 특이점이 많이 나온다 느꼈는데요. 아무래도 디자인너 분들과 컴포넌트를 정의하고, 작게 쪼개놓더라도, 유저와 직접 소통하는 부분인 만큼 엣지케이스가 상당히 많이 나온다고 생각했습니다.
예를 들면 완전히 같은 데이터의 에러케이스를 다룰때 역시 화면에 따라 다른 동작을 해야할 때가 많기 때문입니다. 이를테면 서버에서는 완전히 같은 데이터의 에러이지만 상황이 다를때는 일반적으로 내려주는 에러의 타입이나 메시지, status 코드등이 변경됩니다.
물론 설계를 어떻게 하느냐에 따라, 클라이언트와의 약속을 어떻게 하느냐에 따라 순수한 에러는 위로 올리기만 하고 각 endpoint 에서 내려주는 타입을 모든 동작별로 정의 할 수도 있지만, 이렇게 각각의 모든 에러를 정의 하고, 핸들링 하다보면 에러의 타입만 유저의 화면별로 수백, 수천개가 되는경우가 생길수 있기에 권하고 싶지는 않습니다. 물론 권하지 않는다해서 좋지 않다는 뜻은 아닙니다. 모바일 네이티브 어플리케이션의 경우 어떤 기능의 변화를 클라이언트 단에서 컨드롤 하다보면, 하나의 변화가 생길때마다 릴리즈가 일어나야 하는데 이럴때는 서버컨트롤로 유연한 대처를 위한 방안을 모색하는것은 충분히 좋은 방법이란 생각입니다.
이어서 앞단의 이야기를 하자면 완전히 같은 에러이지만 지금 유저가 어느 화면을 보고 있냐에 따라 동작을 처리하는 순서가 달라져야 할 수도 있습니다.
완전히 같은 에러이지만 아래와 같은 상황이 나온다는 것이지요.
ex) 1. 팝업 -> 팝업죽이고 -> 아래에서 토스트 -> 토스트 죽이고 이전화면으로
ex) 1. 아래에서 토스트 -> 토스트 죽이고 이전화면으로 -> 이전 화면에서 팝업
코드의 깊이에 대한 요지는 다음과 같습니다.
- 추상화를 맞추려 노력하자
- 이게 맞추어진다면 언제 어디서 코드를 읽어도 동일한 깊이의 함수를 읽음으로서, 처음보는 코드를 파악하는데 드는 리소스가 적어진다.
- 길지 않은 코드가 무조건 좋은 코드는 아니다. 반대 역시 마찬가지이다.
- 리얼월드에서 한 파일에 수천 수만줄의 코드로 작성된 경우를 직접 다루어 보았으나, 이부분은 노력 한다면 분명히 나아진다.
- 추상화를 맞춘다는 것의 의미는, 각 계층별 역할이 분명한 상태이고, 이 계층별 함수 하나하나가 동작별로 잘 나뉘어진 상태라는 것을 의미한다.
- 이 작게 나뉘어진 함수가 같은 계층에서 같은 추상화의 수준을 유지한다면, 함수간 협력, 객체간 협력을 설계하기 위한 경계선이 비교적 선명히 드러나기 시작한다.
이정도면 깊이, 추상화의 기본적인 개념은 다룬것 같은데요. 그럼 이제 응집에 대한 이야기를 해볼까 합니다. 사실 이 응집과 추상화 라는 주제는 서로 떼놓을 수 없다고 생각하는 주제인대요. 저 추상화를 올바르게 맞추고 깊이를 동일히 유지하기 위해서는 코드의 응집이 꼭 필요하기 때문입니다.
응집된 코드란 무엇일까
우리는 객체지향 프로그래밍. 혹은 클린아키텍처, 클린코드란 주제를 읽으며 객체의 책임과 응집. 코드의 응집. 함수의 응집 등등 많은 곳에서 응집이라는 단어를 접해왔을 것입니다. 물론 관련한 좋은 책들을 읽고, 충분히 이해를 하신 엔지니어분들도 무수히 많겠죠. 그러나 우리의 리얼 월드에선 왜 이것이 무너질까요. 저의 지극히 개인적인 생각은, 귀찮다는 이유로 회피했기 때문이라는 생각이 가장 큽니다.
서비스의 크기가 작고, 팀의 크기가 작을때는 이런 개념들 없이 충분히 코드를 작성하는데 무리가 없었기 때문이죠. 하지만 서비스가 성장함에 따라 이 기본적인 개념들을 지키지 않은 코드는 유지보수가 굉장히 힘든 코드로 발전해 나아가는 경우가 더 많다고 느꼈습니다. 여러분. 이 개념을 잘 지킨다고 해서 절대 생산성이 떨어지지 않습니다. 제 개인적인 기준에서 이 개념을 지킨다고 생산성이 떨어진다는 것은
- 익숙치 않거나
- 내 실력이 부족한 것 입니다.
- 저는 어쩌면 둘다에 해당한달까요...? 🥲
그럼 응집의 개념에 대해 알아보겠습니다. 이 주제 역시 개념자체는 그리 어려운 개념이 아닌데요. 설계와 관련한 부분에 고민을 시작하신지 얼마 안된 분들의 경우 미묘하게 애매한 부분이 생기기 참 쉽다고 생각합니다. 이중 제가 생각하기에 가장 쉬운 예시를 들어보겠습니다.
- 유저의 아이디가 파라미터로 넘어오는 상황입니다.
- 유저와 유저의 주소 데이터를 찾아야 합니다.
- 굉장히 간단한 상황이네요?
- 이 간단한거 어차피 유저아이디가 들어오니 유저서비스에 함수를 작성하면 될 것 같습니다.
- 오우... 프로젝트가 커지니 이거 유저에 주소를 찾는 부분이 user, user_address, order, user_card 등등 수많은 서비스에 다 있네요. 이부분에 무언가를 고치기가 굉장히 곤란해 졌습니다.
어떤 상황인지 짐작이 가시나요?
이것은 특정 레이어에만 한정된 주제가 아닙니다. 전체적 전반적인 부분에 해당하는 주제입니다.
이를테면 User 라는 Entity 에서 특정 값에대한 검증을 하는 로직을 혼자만 가지고 있다면 이 Entity 를 사용하는 어플리케이션은 전체적으로 모두 같은 검증로직을 사용한다는 보장을 받을 수 있을 것 입니다.
혹은 id 라는 값을 가지고 유저를 찾아내는 로직을 UserService 라는 녀석만이 가지고 있다면 어플리케이션 전체적으로 id 를 가지고 유저를 찾아내는 로직은 모두 동일하다는 보장을 받을 수 있습니다.
즉 서비스 계층을 예로 들자면 아래와 같은 상황을
func 유저의 아이디가 들어오지만 유저에 주소를 같이 찾아내는 코드(userId int) (*User, *UserAddress) {
user, _ := userRepository.FindById(userId)
userAddress, _ := userAddressRepository.FindByUserId(user.Id)
return user, userAddress
}
func 컨트롤러() {
user, userAddress := 유저의 아이디가 들어오지만 유저에 주소를 같이 찾아내는 코드(userId)
}
아래와 같이 작성하는것을 권장하고 싶습니다.
func 유저의 아이디로 유저를 찾는 코드(userId int) *User {
user, _ := userRepository.FindById(userId)
return user
}
func 유저의 아이디로 유저의 주소를 찾는 코드(userId int) *UserAddress {
userAddress, _ := userAddressRepository.FindByUserId(userId)
return userAddress
}
func 컨트롤러() {
user := 유저의 아이디로 유저를 찾는 코드(userId)
userAddress := 유저의 아이디로 유저의 주소를 찾는 코드(userId)
}
현업에서 적용중인 부분을 살짝 미리 말씀드리자면, 저 두가지 행위가 묶인 개념의 행동을 정의하는 함수는 이후 공통적인 관심사로 이루어지는 구간이 굉장히 반복이 된다할때 떼어내는것을 추천하고 싶습니다.
물론 정말 도메인 단위와 usecase 별로 빡센 DDD 를 구현하기 시작하다 보면 더 큰개념을 생각해야 할 수도 있습니다. 다만 가장 작은 database model 단위에서의 접근을 주로 하는 Repository 단이나 이를 한단계 위의 계층에서 접근하는 Service 단의 응집도를 잘 정리해두지 않으면 위 단계의 설계로 넘어갈때 고생을 할 가능성이 비교적 높아지는 경우가 많다고 느꼈습니다.
Repository 라면 유저라는 모델에 관한 쿼리를 하는 Repository 는 가능한 userRepository, userReadRepository, userWriteRepository 가 되어야 한다는 뜻입니다.
물론 read 의 경우 join 이 불가피할 경우도 있고, 혹은 다른 무언가의 영향을 받을 가능성이 굉장히 큰 관심사이긴 합니다만. 이런 경우 어떠한 동작에 대한 Repository 를 따로 관리하는 것을 추천합니다. 즉 제가 말하고 싶은 포인트는 다음과 같습니다.
어플리케이션 전체를 통틀어 하나의 관심사에 대한 특정 기능은(userId 로 유저를 찾는다던지, userName 으로 유저를 찾는다던지), 불가피할 경우를 제외하곤 하나만을 유지하도록 노력하는 것이 중요합니다. (개인적으론 아직 불가피한 상황은 만나보지 못했습니다..)
정리
내용을 정리하자면 다음과 같습니다.
- 어플리케이션의 각 계층엔 각자의 역할이 존재합니다.
- 이들은 각자의 역할에 따라 본인이 갖는 관심사가, 명확하고 분명히 정의되어야 합니다.
- 관심사나 역할의 경계가 명확할 수록 이들의 응집력은 높이기 수월해지고, 이를 명확하게 하기 위해서는 가장 깊은곳의 계층에서 부터 그 단위를 가능한 작게, 명확히 가져가야 합니다.
- 계층의 깊이가 깊을수록 구현체는 하나의 동작을 정의합니다.
- 계층의 깊이가 얕을수록 구현체는 서로 협력하여 하나의 행동을 정의합니다.
마치며
늘 글의 마지막엔 비슷한 이야기를 하게 되는것 같은데요. 정답이란건 없다 생각합니다. 다만 오답은 있다고 생각합니다. 이 글이 깨끝한 어플리케이션을 작성하기 위한 기반을 이해하며, 레이어의 기본적인 개념을 이해하기 위한 부분에 도움이 되었으면 하는 바램입니다.
기회가 된다면, 리얼월드에 가까운 예시를 직접 구현하며 여태 정리해온 개념을 코드로 만나보는 시간을 갖을 수 있도록 해보겠습니다. 긴글 읽어주셔서 감사합니다.